Tópicos
- Modelos de serviços em computação em nuvem
- Tipos de usuários dos serviços em cloud computing
- Funcionamento dos serviços em cloud computing
- Backup e recuperação
- Compactação de dados e consolidação do datacenter
- Arquivamento de dados, recuperação de desastres, FAST
- Modelos de serviços
- Replicação, gerenciamento de armazenamento, desduplicação
Modelos de serviços em computação em nuvem
O mercado de Tecnologia da Informação tem a sua disposição modelos de serviços que englobam computação nas nuvens. Provedores de soluções em nuvem oferecem seus serviços na forma de Infraestrutura, Plataforma ou Sistema (Software). Esses serviços são oferecidos em mais de uma categoria. Nesta tópico, examinaremos essas categorias, que representam os modelos de serviços mais fornecidos no mercado mundial em termos de soluções em nuvem.
Os modelos de serviços representam o limite entre as responsabilidades, gerenciamento e a rede do cliente e as do provedor de serviços em nuvem. São definidos pelo NIST (National Institute of Standards and Technology), Instituto Nacional de Padrões e Tecnologias americano.
Os modelos de implantação ligados ao acesso e à disponibilidade de ambientes de computação em nuvem e podem ter restrições com relação à abertura ou acesso, dependendo do processo de negócio e também do tipo de informação. Podem ser divididos em nuvem pública, privada, comunidade e híbrida.
Uma das vantagens dos serviços em computação em nuvem é o fato da possibilidade de requisição de maior ou menor quantidade de recursos computacionais conforme a necessidade. Recursos como tempo de processamento, armazenamento de dados, largura de banda, entre outros, podem ser disponibilizados sem interação do usuário, de forma automática, com o provedor de cada serviço.
O mercado de tecnologia da informação tem à sua disposição modelos de serviços que englobam computação nas nuvens (Figura 1).
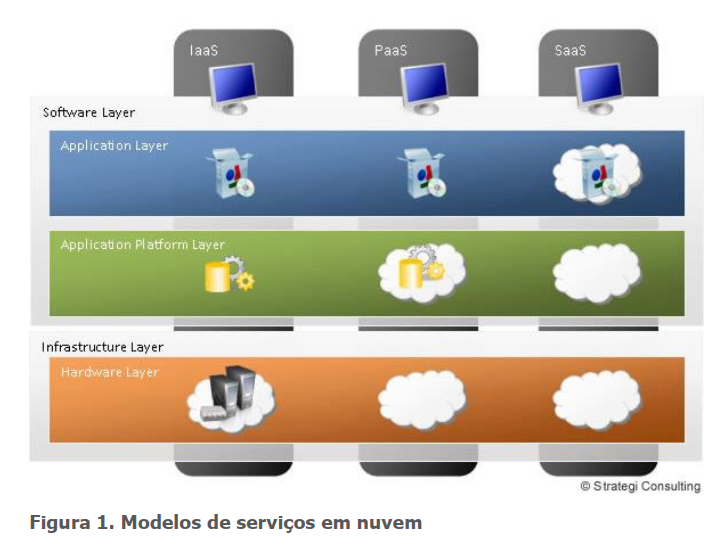
Provedores de soluções em nuvem oferecem seus serviços na forma de infraestrutura, plataforma ou sistema (software). Tais serviços são oferecidos em mais de uma categoria. Esses modelos são definidos pelo NIST (National Institute of Standards and Technology) – o Instituto Nacional de Padrões e Tecnologias americano.
Veremos aqui estas categorias que representam os modelos de serviços mais fornecidos no mercado mundial em termos de soluções em nuvem (Figura 2):
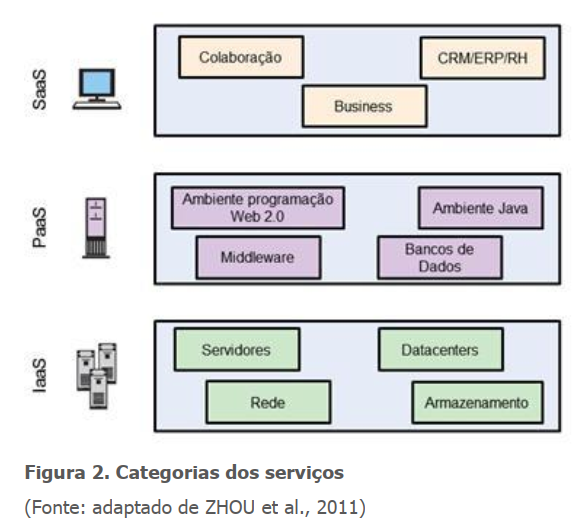
- Cloud Software as a Service (SaaS) – Software/aplicação vendido na nuvem;
- Cloud Plataform as a Service (Paas) – Aplicação do cliente implementada na nuvem;
- Cloud Infrastructure as a Service (IaaS) – Venda de processamento, storage, rede, memória, máquinas virtuais e recursos computacionais na nuvem.
Os modelos de serviços representam o limite entre as responsabilidades, gerenciamento e a rede do cliente, e as do provedor de serviços em nuvem.
Modelos de implantação
Esses modelos estão ligados ao acesso e à disponibilidade de ambientes de computação em nuvem e podem ter restrições com relação à abertura ou ao acesso, dependendo do processo de negócio e também do tipo de informação.
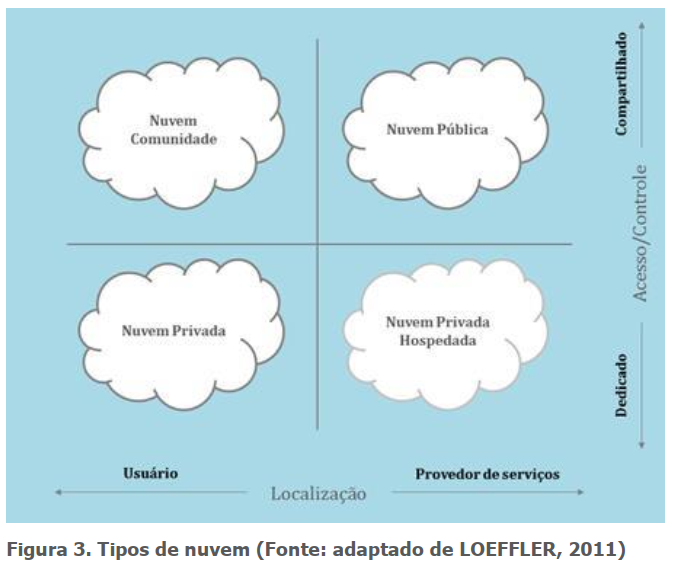
Nuvem privada – A infraestrutura é utilizada exclusivamente por uma organização, podendo ser local ou remota. Nesse caso, são empregadas políticas de acesso aos serviços.
Vantagens:
- Maior aproveitamento de máquinas como servidores, explorando ao máximo a capacidade de cada uma individualmente;
- Centralização no ambiente de data center, beneficiando o gerenciamento e reduzindo a complexidade de TI;
- Escalabilidade dos recursos através da criação de novas máquinas virtuais e provisionamento desse crescimento;
- Redução nos custos com aquisição de novos equipamentos e ainda com energia elétrica e ar condicionado;
- Aumento de segurança com firewalls, soluções de backup e afins centralizados no data center.
Nuvem privada hospedada – A infraestrutura de nuvem situa-se de modo remoto.
Nuvem pública – A infraestrutura é disponibilizada para o público em geral, podendo ser acessada por qualquer usuário que conheça a localização do serviço. O fornecedor é um fabricante, e os clientes são diversas empresas.
Nesse tipo, os serviços são oferecidos com configurações específicas de forma a atender os casos de uso mais comuns. Em se tratando de processos com necessidades de segurança elevada, esse tipo não é o mais adequado.
BENEFÍCIOS:
•O provisionamento de infraestrutura e de serviços é simples;
•É possível converter gastos de capital em despesas operacionais;
•Usuários pagam pelo que usam;
•Não é necessário realizar a administração da infraestrutura física subjacente.
Nuvem comunidade – A infraestrutura é compartilhada e oferece suporte a uma comunidade específica com preocupações comuns. A administração fica ao cargo de uma das organizações pertencentes à comunidade (Figura 4).
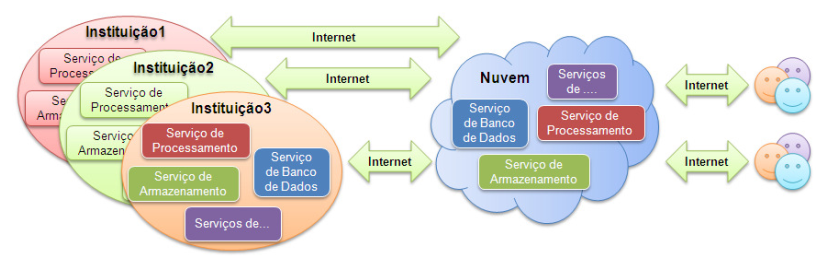
Este tipo de modelo de implantação pode ser de forma local ou remota e pode ser gerenciada e operada por uma ou mais organizações pertencentes à comunidade, por terceiros ou alguma combinação destes.
Nuvem híbrida – Representa uma composição de duas ou mais nuvens que permaneçam como entidades exclusivas, agrupadas por tecnologia padrão. Pode haver portabilidade de dados e aplicativos. Representa a junção dos serviços que estão sendo executados em uma nuvem pública e uma nuvem privada.
Esse tipo tem como limitação a dificuldade de criação e administração para uma solução desse porte. Serviços de diferentes fontes devem ser obtidos e disponibilizados como se fossem originados de um único local, e as interações entre componentes públicos e privados podem tornar a implementação ainda mais complicada.
Tipos de usuários dos serviços em cloud computing
Entre os usuários de serviços em cloud computing, podemos destacar entidades governamentais e empresas que usam os serviços de computação em nuvem de forma a satisfazer suas necessidades de infraestrutura e aplicativos. Temos como exemplos mais característicos CRM e banco de dados, abrangendo computação e armazenamento de dados. Vale ressaltar que, nesse tipo de serviço, a entidade ganha na não obrigatoriedade de custos antecipados tanto de software como de hardware, e também na questão do tempo, pois o fornecimento dos serviços e recursos de TI é disponibilizado prontamente, criando uma associação entre custo e utilização.
Dessa forma, as organizações têm maior agilidade e podem gerenciar as despesas com mais eficiência. Da mesma forma, os consumidores usam esses serviços para simplificar o uso, o armazenamento, o compartilhamento e a proteção de conteúdo de aplicativos, permitindo acesso por qualquer dispositivo conectado à web.
Entre vários, podemos citar os seguintes benefícios que as entidades obtêm:
- Implementação e tempo de implantação mais rápidos;
- Acesso aos aplicativos e ao conteúdo em qualquer lugar;
- Redimensionamento rápido para atender à demanda;
- Maior utilização de investimentos em infraestrutura;
- Menores custos de infraestrutura, energia e instalação;
- Maior produtividade da equipe de TI e da organização;
- Maior segurança e proteção dos ativos de informação.
Os serviços de computação em nuvem podem auxiliar as empresas, oferecendo espaço dentro da rede.
Deve-se levar em consideração que serviços que possuem muitos usuários logicamente terão necessidade de muito processamento e, consequentemente, grande fluxo de dados e a possibilidade de muito espaço para armazenamento das informações.
Para resolver tal problema, a empresa poderá contratar mais espaço nos servidores na nuvem e garantir o funcionamento do serviço seja qual for a demanda.
Outra questão fundamental é relacionada com a independência que afeta diretamente os dispositivos e a localização, permitindo aos usuários acesso aos sistemas através de navegadores independentemente da sua localização e do sistema operacional. Como a infraestrutura é fornecida por outro agente, o usuário poderá se conectar em qualquer lugar que esteja.
Também é importante abordar a questão do compartilhamento de recursos e custos por vários usuários, garantindo uma centralização de infraestrutura.
O termo consumo de serviços, por exemplo, também está relacionado a um usuário final ou organização que utiliza os serviços de cloud computing, podendo ser software, plataforma ou infraestrutura. Nesse caso, pode haver a possibilidade de implantação de regras de serviços para disponibilizar diferentes interfaces de usuário e também de programação.
Nos diversos tipos de usuários, também temos interfaces específicas para o preenchimento de funções administrativas, principalmente sobre máquinas virtuais e controle de armazenamento. Mas esse fato não implica diretamente em obrigação de ter conhecimentos sobre cloud computing para a utilização de uma aplicação nela hospedada. Sendo assim, o provedor disponibiliza os serviços para o usuário (consumidor).
Funcionamento dos serviços em cloud computing
É importante frisar que computação em nuvem é uma forma de entrega de infraestrutura e aplicações – e, como tal, possui alguns atributos de valores que deverão ser considerados para adoção de serviços em cloud computing. Entre outros fatores, as organizações buscam benefícios na utilização desses serviços que tenderão a garantir maior produtividade e com baixos custos operacionais.
Eis alguns desses benefícios:
- Acessibilidade de qualquer lugar;
- Serviços e infraestruturas sempre disponíveis;
- Compatibilidade das aplicações de acordo com os interesses da organização;
- O setor de TI se concentra de forma direta no tipo de negócio da organização;
- Segurança das aplicações.
Outro fator muito importante em serviços de computação em nuvem é a troca de servidores e ferramentas que poderão ser disponibilizados de forma bem criteriosa e de acordo com as necessidades de cada usuário.
Tal serviço impõe de certa forma algumas condições para seu desempenho adequado, e o mais importante é possuir um bom link de internet.
Veremos agora algumas formas de disponibilização de serviços de computação em nuvem:
- Virtualização – virtualização de servidores e armazenamento para alocar e realocar recursos de forma rápida;
- Multi-tenancy – agrupamento e compartilhamento de recursos entre vários usuários para obter economia de escala;
- Sob demanda – os recursos são disponibilizados de acordo com configurações predefinidas;
- Elástico – os recursos podem fazer scale-up ou down automaticamente;
- Scale-up – uma configuração dinâmica de máquinas virtuais que possibilita que as mesmas sejam redimensionadas de forma dinâmica de acordo com as demandas do ambiente;
- Scale-out – uma configuração que possibilita a utilização de um balanceador de carga, de forma a ter mais de uma máquina respondendo por um mesmo serviço, permitindo que um ambiente possa ser facilmente ampliado horizontalmente;
- Medição/chargeback – controle de uso dos recursos que são monitorados e cobrados de acordo com o contrato de serviço.
Atributos definidos para cloud computing
- Baseado em serviço – Tem a mesma conotação de serviços sob medida. Determinado para atender a necessidades específicas de um grupo de clientes. Nesse caso, a tecnologia é escolhida para atender diretamente à solução ou ao serviço específico;
- Escalável e elástico – O serviço pode ser escalado de acordo com demandas específicas. A elasticidade é aplicada em ambientes em que possuem recursos compartilhados de TI. A escala é um requisito ligado à infraestrutura e a software;
- Compartilhado – O compartilhamento de serviços facilita a economia de escala, propiciando o máximo de eficiência para os recursos de TI. Nesse caso, infraestrutura, software ou plataformas são compartilhados entre vários usuários dos serviços, permitindo o fornecimento de recursos para atender às necessidades de múltiplos clientes ao mesmo tempo;
- Medido por uso – Adoção de diferentes modelos de pagamento em que a cobrança normalmente será pelo uso, por número de usuários, por planos limitados etc. Sempre será pelo uso do serviço.
Backup e recuperação
Levando-se em consideração que muitas informações são restritas ou críticas para as empresas, a segurança de dados é uma das maiores preocupações na migração para cloud computing. Essa migração poderá trazer mais flexibilidade e economia de recursos desde que sejam levadas em consideração as questões de segurança por criptografia e ferramentas que sempre recebem atualizações constantes por parte dos fornecedores. Para tal, tomar medidas de segurança é um elemento primordial para a integração dos dados, e nesse sentido backup e recuperação são fundamentais.
Backup e recuperação representam a criação de cópias de dados (backups) para que os mesmos possam ser restaurados ou recuperados para um estado anterior caso sejam perdidos ou corrompidos. Praticamente todas as empresas dependem de backup e recuperação para manter a continuidade de negócios. Caso os dados de negócios sejam perdidos, é possível recuperá-los a partir de uma cópia de backup.
Normalmente o backup dos dados é feito regularmente, por exemplo, uma vez a cada 24 horas. Nesse processo, são criadas uma ou mais cópias, duplicadas ou desduplicadas (A deduplicação ou desduplicação de dados é uma técnica para eliminar cópias duplicadas de dados repetidos. Um termo relacionado e um tanto sinônimo é o armazenamento de instância única. [Wikipédia]), dos dados primários que são gravados em um novo disco ou fita.
Torna-se necessário para a recuperação de desastres, transporte ou replicação de forma externa a fim de garantir que os dados estejam seguros caso ocorra um desastre.
Entre as ações que as empresas têm no seu dia a dia, a proteção das informações é fundamental, uma vez que essas informações representam um dos ativos da empresa, e ter uma estratégia de backup e recuperação eficiente e gerenciável tornou-se fundamental para o setor de TI.
Para essas ações, é necessário que a empresa faça uma análise das principais tecnologias e recursos usados para backup de máquinas virtuais e recuperação de desastres em ambientes de cloud computing. É fundamental que se faça uma avaliação do espaço necessário para a implementação de uma política de backup na nuvem. Também é importante a escolha de um software de automatização de backups.
Normalmente as ferramentas de backup na nuvem fazem um backup local, e após essa rotina é que é feita a cópia para a nuvem. Backup e recuperação baseados em nuvem têm a vantagem de serem flexíveis, garantindo uma personalização mesmo com mudança nos negócios ou a sua evolução.
Veremos alguns serviços de backup online: Dropbox, OneDrive, Google Drive, MEGA, Copy, entre outros.
Backup automático
Com a intenção de evitar falhas e perda de informações, é necessário manter uma cópia dos dados essenciais para uma empresa. A prática de manter backups automáticos garantirá a proteção dos arquivos. Para tal, há diversos servidores que são utilizados para evitar perda de dados em caso de falhas.
Privacidade de acesso
O acesso pode ser feito a qualquer hora e de qualquer lugar, pois basta uma conexão com a internet por meio de um computador ou até mesmo de dispositivos móveis. Com esse recurso, fica muito mais fácil ter acesso a um arquivo, porém medidas de segurança devem ser tomadas, como:
- Controle de acesso de usuários;
- Senhas;
- Criptografia na transmissão de dados;
- Criação de VLANs e VPN.
Otimização de tempo
É essencial para as empresas que seus dados continuem em sigilo e livres de ataques, e em cloud computing as questões de segurança e atualização dos servidores passam a ser de responsabilidade do fornecedor. Com isso, a empresa ganha tempo.
Recuperação de dados
No caso de perda de armazenamento, os sistemas de cloud computing possuem avançados recursos de recuperação de dados. As cópias de segurança dos aplicativos e bancos de dados serão automatizadas, e a recuperação
acontecerá de forma simples. Essa possibilidade de recuperar o serviço após uma falha grave poderá ser a solução dos problemas de perdas.
Um plano de recuperação é fundamental, e é necessário conhecer os locais de armazenamento de dados de uma empresa a fim de saber o procedimento para recuperação em caso de catástrofe. A não replicação de dados e de infraestrutura em diversas localidades poderá representar uma falha com possíveis danos à integridade dos dados. Também é importante comentar sobre a frequência de backup que pode ser configurado de acordo com as preferências do usuário.
Replicação e espelhamento de dados críticos de negócios ocorrem através do uso de múltiplas localizações geográficas para, assim, haver um mínimo de paralisação das operações em caso de falha. Os serviços de armazenamento devem conter áreas similares para arquivos deletados, porém, com relação a prazo de manutenção, isso varia bastante de acordo com as políticas dos serviços.
Normais governamentais
O Tribunal de Contas da União (TCU), através da fiscalização de tecnologia da informação, publicou o seguinte texto:
Diante desse cenário, a Secretaria de Fiscalização de Tecnologia da Informação (Sefti), com apoio da Secretaria de Infraestrutura de TI (Setic), realizou um levantamento com objetivo principal de identificar riscos em contratações na Administração Pública Federal (APF) sob o modelo de computação em nuvem, que, sob relatoria do Ministro Benjamin Zymler, resultou no Acórdão 1.739/2015-TCU-Plenário. A equipe elaborou uma tabela de riscos e possíveis controles associados à contratação desses serviços e uma matriz de referência contendo questões, procedimentos e possíveis achados de auditoria, de modo a auxiliar os auditores do TCU em futuras fiscalizações. (Acórdão 1.739/2015 -TCU-Plenário)
Compactação de dados e consolidação do datacenter
O uso de banco de dados em cloud computing é uma forma de registrar e armazenar informações dos usuários de maneira confiável e segura. Essa prática tem recebido fortes investimentos por parte das empresas com a intenção de fornecer ao usuário métodos seguros para armazenamento de dados, contando com acesso e recuperação de forma simples.
Banco de dados na nuvem, do inglês Database as a Service (DBaaS), também conhecido como banco de dados como serviço, é a disponibilização de um software de banco de dados, como um serviço, que se encontra alocado fisicamente no data center do fornecedor ou provedor.
Um banco de dados na nuvem tem algumas características:
- Serviço disponível para os usuários sob demanda, sem qualquer exigência para a instalação e configuração de qualquer hardware ou software máquina a máquina, sendo a sua utilização totalmente virtual;
- O serviço é fornecido em forma de assinatura, levando em consideração a capacidade de armazenamento e processamento, assim como desempenho;
- O fornecedor/provedor é responsável pela gestão do serviço sem que o cliente tenha responsabilidade para manter, atualizar ou administrar seu banco de dados.
Redução de custos
Quase que de forma personalizada, as empresas utilizam serviços de banco de dados e suas funcionalidades conforme necessário para sua operação. Como a manutenção é feita pelo fornecedor, não é necessária a contratação de profissionais específicos, e isso representa uma boa redução de custos.
Rapidez de provisionamento
Instalações e atualizações são feitas automaticamente, com ganho de tempo.
Escalabilidade facilitada
A capacidade de desempenho do banco de dados poderá ser aumentada de acordo com a evolução dos negócios da empresa.
Segurança e confiabilidade
As tarefas de backup, recuperação, tuning, otimização, patching e modernização são de responsabilidade do provedor e podem ser automatizadas ou agendadas com antecedência.
Compactação de dados
Compressão ou compactação de dados é uma estratégia que reduz o espaço de armazenamento físico e consequentemente melhora as taxas na transferência de dados.
Isso se dá também em aplicações distribuídas, obtendo melhor desempenho em aplicações sobre os dados.
A compactação de dados reduz o tamanho dos dados no disco e, dessa forma, aumenta a capacidade disponível em até 50%. O processo de ativação da compactação pode ser feito de forma automática e funciona em segundo plano para evitar degradação no desempenho.
Uma solução de armazenamento em blocos pode se beneficiar da compactação de dados em blocos. Essa compactação é gerenciada como um atributo de volume, sendo fácil a sua ativação, e pode ser configurada e monitorada sem a obrigatoriedade de conhecimento específico pelo usuário.
A compactação de dados é um recurso usado amplamente em várias camadas de aplicativos, incidindo sobre dados principais de backup e de arquivo. Compacta dados conforme eles são gravados nos sistemas.
Essa prática ajuda no controle de proliferação de dados. O uso dos recursos de redução de dados oferece uma vantagem imediata que é mantida em todo o ciclo de vida dos dados.
A compactação de dados libera capacidade de armazenamento com sobrecarga mínima do desempenho. A compactação aplica-se a todos os dados, resultando em economia de capacidade de até 50%.
Consolidação do data center
Representa uma redução do volume de ativos físicos de TI utilizando tecnologias altamente eficientes e dimensionáveis. Essa prática tem tido muito sucesso em redução de custos operacionais.
A consolidação do data center é normalmente utilizada para mesclar vários data centers em um ou para reduzir o tamanho de um único data center.
É possível consolidar vários aplicativos em uma infraestrutura de TI compacta e mais eficiente, adotando tecnologias de soluções de armazenamento de maior densidade e virtualização de armazenamento e servidor, criando, assim, um data center mais dinâmico.
A consolidação promove melhorias, permitindo que as organizações ganhem mais consistência e controle de seus ativos de data center, com economia em grande escala de custos e consumo de energia.
Arquivamento de dados, recuperação de desastres, FAST
De tempos em tempos é necessário identificar e mover dados inativos dos sistemas atuais de produção para os sistemas de armazenamento e arquivamento especializados de longo prazo. Essa ação é denominada de arquivamento de dados.
Esse processo retira dados inativos dos sistemas de produção e contribui para a otimização do desempenho de recursos necessários. Dessa forma, os sistemas de arquivamento armazenam informações com certa economia, proporcionando recuperação quando se tornar necessário.
É fundamental para as empresas que possuem informações acumuladas, tanto as antigas quanto as novas, manter um arquivamento de dados. As determinações por parte de órgãos governamentais é que se mantenha as informações pelo maior tempo possível, com um maior número disponível de informações e com rotinas de recuperação cada vez mais rápidas; assim, nesse sentido, o arquivamento automático de dados contribui para atingir essas práticas com custos bem menores.
Normalmente fica por conta da empresa a criação de políticas para a determinação dos dados que deverão ser movidos para arquivos, identificando e mudando-os para o sistema de arquivamento. Após essa mudança, as informações estarão on-line e prontamente acessíveis, tendo seu conteúdo original preservado e garantindo a integridade daquelas que foram devidamente arquivadas.
Normalmente há um crescimento exponencial dos dados corporativos, e é necessário que as empresas tenham um acompanhamento desse aumento. O arquivamento de dados proporciona uma diminuição de custos de implantação e gerenciamento.
Benefícios
- Ter o processo de arquivamento de dados automatizado garante um funcionamento mais adequado dos sistemas de produção, utilizando menos recursos e consequentemente com redução de custos de armazenamento;
- Também é importante ressaltar que essa prática contribui para que o backup e a recuperação sejam executados de forma bem mais rápida;
- E, em termos de custo de armazenamento, também é obtido um ganho nos dados que são movidos para os arquivos de armazenamento.
Algumas ações de ganhos obtidas pelo arquivamento de dados:
- Gerenciamento do crescimento de conteúdo;
- Indexação automática de conteúdo;
- Melhor controle sobre versões, inclusive as antigas dos mesmos arquivos;
- Eficiência nas políticas de retenção para os arquivos;
- Melhor gerenciamento de informações;
- Redução do espaço ocupado pelos dados com centralização e integração de informações de várias fontes para o arquivamento;
- Melhora de desempenho e escalabilidade;
- Tempos de resposta menor às solicitações de descoberta e investigação;
- Acesso transparente aos arquivos
Recuperação de desastres
Todos os componentes de TI (hardware, software e dados) são residentes em um data center. Por essa razão, é imprescindível que haja uma política de proteção com soluções à prova de falhas.
Mas sempre há o risco de forças que normalmente estão além dos controles das políticas implantadas, como desastres naturais, eventos provocados pelo homem e procedimentos de segurança ou interrupção dos serviços. Essas forças podem proporcionar um tempo de inatividade e a perda temporária de dados, o que pode impactar de forma negativa nos negócios de uma organização.
O plano de recuperação de desastres, DRP (disaster recovery plan), prevê procedimentos que deverão ser adotados sempre que ocorrer uma falha devido a alguma inconsistência provocada em virtude de ameaças, como incêndios, inundações, vandalismo, sabotagem ou falhas de tecnologia.
Fases do DRP:
- Programa de administração de crise – plano desenvolvido em conjunto, com definição de atividade, pessoas, dados lógicos e físicos;
- Plano de continuidade operacional – possui diretivas do que fazer em cada operação em caso de desastres;
- Plano de recuperação de desastres – aplicação na prática do plano de continuidade operacional.
Para a escolha de uma estratégia de recuperação de desastres, é necessário ter em mente o plano de continuidade de negócios da organização, indicando as métricas de objetivo de ponto de recuperação (RPO) e objetivo de tempo de recuperação (RTO) para os processos de negócios. A especificação dessas métricas levam em consideração os sistemas de TI e infraestrutura.
RPO significa objetivo de ponto de recuperação. Define o volume máximo de perda de dados admissível. RTO significa objetivo de tempo de recuperação que será definido como o tempo máximo aceitável para a restauração das bases de dados.
Redundância
A fim de garantir uma recuperação de dados e infraestrutura, é necessário montar e manter um data center primário com redundância de dados e de equipamentos para evitar a perda de informações. É válido ter um data center secundário onde será replicada a infraestrutura de TIC e os dados armazenados.
FAST
Fully Automated Storage Tiering, armazenamento com classificação totalmente automatizada por níveis.
É um recurso que movimenta automaticamente dados ativos para níveis de armazenamento de alto desempenho e dados inativos para níveis de armazenamento de alta capacidade e baixo custo. Com isso, é obtido um maior desempenho, menores custos e espaço físico menor do que o dos sistemas convencionais.
Modelos de serviços
Como foi apresentado anteriormente, de acordo com a definição do NIST (Instituto Nacional de Padrões e Tecnologia do Departamento de Comércio norte-americano), existem três modelos de serviços e quatro formas de implantação que compõem o modelo de computação em nuvem.
SaaS (Software as a Service, software como serviço)
É a camada mais externa do modelo conceitual, composta por aplicativos que são executados no ambiente da nuvem. Podem ser aplicações completas ou conjuntos de aplicações cujo uso é regulado por modelos de negócios que permitem customização.
Modelo no qual o software é executado em computadores do provedor de SaaS e por ele gerenciados. Portanto, não é instalado e gerenciado nos computadores do usuário. O acesso é feito pela internet pública e, em geral, é oferecido com assinatura mensal ou anual.
Esse modelo de serviço oferece ao usuário a utilização da aplicação fornecida pelo provedor, rodando em uma infraestrutura de computação em nuvem.
Trata-se de uma infraestrutura invisível para o cliente, pois todo o gerenciamento, como espaço em disco, capacidade de rede, sistema operacional ou servidores, fica a cargo do provedor de serviços.
A infraestrutura necessária estará na nuvem, proporcionando mais tempo livre para a equipe de TI para outras tarefas.
Esse modelo é utilizado normalmente para aplicações de acesso remoto ou móvel, como, por exemplo, os softwares de CRM (gestão de relacionamento com o cliente) e gestão de redes sociais, marketing e pessoas.
Quando as aplicações necessitarem de processamento de dados rápido ou em tempo real, esse modelo não é recomendado.
Vantagens:
- Aplicativos disponíveis a partir de quaisquer computadores ou dispositivos computacionais, a qualquer hora e em todos os lugares;
- É cobrado apenas o valor pela utilização, sem taxas de licença;
- As atualizações são transparentes e de única responsabilidade do provedor;
- Os provedores podem escalar sua infraestrutura de forma indefinida para atender à demanda de um cliente.
IaaS (Infrastructure as a Service, infraestrutura como serviço)
Esse modelo é apoiado em soluções de virtualização. Nesse tipo de serviço, ações como processamento, armazenamento, sistema de rede e outros são fornecidos pelo provedor de IaaS via internet pública, VPN (Virtual Private Network, rede privada virtual) ou conexão de rede dedicada. Nesse caso, os usuários são proprietários e administradores dos sistemas operacionais, aplicativos e informações executados na infraestrutura, mesmo sendo invisíveis para ele, e normalmente isso é pago conforme o uso.
Nesse modelo de serviço, existe a possibilidade de criação de um data center virtual em que se pode instalar e rodar vários softwares e sistemas em qualquer quantidade de máquinas.
Tem como base a camada inferior do modelo conceitual composta por plataformas para o desenvolvimento, teste, implantação e execução de aplicações proprietárias. Dessa forma, o fornecimento de recursos torna-se mais fácil para um ambiente sob demanda tanto para sistemas operacionais como para aplicativos.
Esse modelo torna possível a transparência de processamento e armazenamento por parte do provedor.
É normalmente usado em casos de demanda volátil, como, por exemplo, nas lojas virtuais e em organizações sem capital para infraestrutura.
Não é aconselhável quando os níveis de desempenho necessários para as aplicações tiverem limites de acesso ao provedor.
Vantagens:
- Redução de investimentos em hardware;
- Eliminação de custos com segurança e manutenção;
- Otimização do desempenho;
- Liberação de espaço físico nas organizações;
- Flexibilidade para ampliar e reduzir a capacidade de processamento e/ou armazenamento.
PaaS (Platform as a Service, plataforma como serviço)
É o modelo que apresenta uma camada intermediária do modelo conceitual composta por hardware virtual disponibilizado como serviço. Tais serviços podem ser sistemas operacionais, banco de dados, serviços de mensagens, serviços de armazenamento de dados etc.
Nesse modelo, os produtos de software e hardware necessários para construir e operar aplicativos em nuvem são fornecidos pelo provedor de PaaS via internet pública, VPN (Virtual Private Network, rede privada virtual) ou conexão de rede dedicada. O pagamento é feito conforme o uso da plataforma, e os aplicativos utilizados no decorrer do seu ciclo de vida são controlados pelos usuários.
O usuário pode instalar e gerenciar as próprias aplicações (desenvolvidas por ele ou adquiridas de terceiros). A infraestrutura também é invisível para ele, podendo ter as suas aplicações e eventualmente os aspectos referentes ao ambiente utilizado por elas configurados. Sendo assim, as aplicações que rodam numa plataforma como serviço são desenvolvidas especificamente para ela.
Esse modelo é aconselhável quando houver necessidade de trabalhos em equipe, integração e triagem de serviços, além de integração de banco de dados. Devido à necessidade de um ambiente complexo para a aplicação, esse serviço é útil no ato da implementação. Outro fator importante é para a interação externa no caso de diversos desenvolvedores atuando mutuamente e em partes.
Não é aconselhável em caso de uso de linguagem proprietária que poderá trazer problemas em situações de mudança para outro fornecedor. Também não é aconselhável nos casos de personalização em que o desempenho do aplicativo exigir hardwares ou softwares específicos.
Vantagens:
- Menor investimento inicial;
- Disponibilização de forma imediata de atualizações e novas funcionalidades;
- Suporte mais ágil com soluções implementadas rapidamente;
- Aumento da disponibilidade e segurança dos dados.
Modelos de implantação
Esses modelos foram apresentados de forma geral e agora serão demonstrados com suas características.
Nuvens privadas
São construídas exclusivamente para um único usuário, que pode ser uma empresa. Nesse caso, a infraestrutura que é utilizada pertence ao usuário com total controle das aplicações. Uma nuvem privada é construída sobre um data center privado.
A característica principal da base para uma nuvem privada é que os recursos de TI são desvinculados de dispositivos físicos.
Características:
- Mais eficiência – os recursos são virtualizados e agrupados, garantindo que sua infraestrutura física seja usada no máximo de sua capacidade;
- Mais agilidade – os recursos de TI podem ser provisionados sob demanda e devolvidos ao pool de recursos com a mesma facilidade;
- Rápida escalabilidade – aloque os recursos de computação adicionais instantaneamente para atender às demandas de negócios devido aos momentos de pico e ao crescimento ou declínio da empresa;
- Custos menores – os custos de infraestrutura, energia e instalação são usados no modelo de “pagamento conforme o uso”;
- Mais produtividade da equipe de TI – provisionamento automatizado por meio do portal de autoatendimento;
- Redução dos recursos desperdiçados – processos transparentes de medição e definição de preços, além de ferramentas de chargeback, permitem que os administradores de TI identifiquem onde pode haver cortes nos custos;
- Maior utilização dos investimentos de TI;
- Mais segurança e proteção dos ativos de informação.
Nuvens públicas
Nesse tipo de modelo, os serviços são apresentados por meio de uma rede aberta para uso público e podem ser livres. A diferença básica para as nuvens privadas reside na questão da segurança, que pode ter problemas de comunicação por conta de uma rede não confiável.
Características:
- O provisionamento de infraestrutura e de serviços é simples;
- É possível converter gastos de capital em despesas operacionais;
- Os usuários de nuvem pública somente pagam pelo que usam;
- Não é necessário realizar a administração da infraestrutura física subjacente.
Nuvens comunitárias
Possuem infraestrutura compartilhada por várias organizações que partilham interesses, como a missão, requisitos de segurança, políticas, entre outros.
Pode ser administrada pelas próprias organizações ou por um terceiro – e pode existir no ambiente da empresa ou fora dele.
Nuvens híbridas
Representa uma composição de duas ou mais nuvens, sejam elas privadas, públicas ou comunitárias. Elas permanecem como entidades únicas, mas estão unidas pela tecnologia padronizada ou proprietária que permite a portabilidade de dados e aplicativos.
A questão da segurança nesse tipo de nuvem é bem acentuada, uma vez que a empresa não necessita expor todos os seus sistemas ou dados para acesso público.
Replicação, gerenciamento de armazenamento, desduplicação
Replicação, por definição, está relacionada a sistema de gerenciamento de banco de dados, representando uma redundância de dados entre vários servidores de banco de dados.
Replicação é o processo de cópia de dados de um array para outro espaço dentro do mesmo array, para um array local separado ou para um array distante. A finalidade pode ser realocar os dados, protegê-los em um segundo local ou colocar os dados em um local de processamento secundário para que as operações possam ser reiniciadas a partir desse local.
Array – estrutura de dados que armazena uma coleção de elementos de tal forma que cada um desses elementos possa ser identificado por pelo menos um índice ou chave.
Replicar ou duplicar – ação de se obter várias cópias gerenciadas de dados para promover uma descentralização de aplicações, backup de servidores de banco de dados, balanceamento de carga e integração de sistemas heterogêneos.
Geralmente a replicação é usada para a proteção de dados contra perda, recuperação de desastres, migração de dados para novos locais e realocação de dados para outros sistemas.
Funcionamento da replicação
Nesse processo, os dados são copiados do local de origem e enviados para um dispositivo de destino via rede, e pode ser em host ou array. A diminuição do impacto sobre os recursos pode ser obtida com a redução de largura de banda larga e compactação de dados. Normalmente, a maior parte da replicação ocorre durante a atividade de produção de forma síncrona (ao mesmo tempo da produção) ou assíncrona (próximo da atividade de produção).
Um dos benefícios da replicação é que reduz o risco de perda de informação e permite que aplicativos essenciais sejam executados em um local secundário, não causando impacto na atividade e nos aplicativos de produção, mesmo que ocorra um desastre ou uma paralisação. A replicação também permite a remoção de dados com facilidade de um local para outro.
A replicação é dividida em duas categorias: replicação de dados em um ambiente de servidor para servidor e replicação de dados entre um servidor e clientes.
A replicação de dados entre servidores normalmente dá suporte a aplicativos e requisitos:
- Melhora da escalabilidade e a disponibilidade;
- Data warehouse e relatórios;
- Integração de dados de vários sites;
- Integração de dados heterogêneos;
- Descarregamento de processamento em lote.
A replicação de dados entre um servidor e clientes inclui estações de trabalho, laptops, tablets e dispositivos. Os dados são replicados entre servidores e clientes, dando suporte aos seguintes aplicativos:
- Troca de dados com usuários móveis;
- Aplicativos POS (Ponto de Venda ao Consumidor);
- Integração de dados de diversos locais.
Unisphere
É um gerenciamento de armazenamento unificado. Consiste em uma plataforma unificada para o gerenciamento de armazenamento a fim de fornecer interfaces do usuário de forma intuitiva para outras plataformas.
A visualização por parte do usuário pode ser personalizada, podendo fazer uma relocação de dados com bastante facilidade. O unisphere também oferece aos usuários uma ampla rede de suporte e colaboração com outros usuários.
Os administradores de armazenamento têm a possibilidade de obter controles intuitivos baseados em tarefas, painéis de controle personalizáveis e acesso com ferramentas de suporte em tempo real e comunidades on-line de clientes.
Desduplicação
Devido ao grande crescimento de dados, existe a necessidade de proteção deles de forma eficaz. A tecnologia de desduplicação é a redução do tamanho dos dados de seus backups.
Essa tecnologia elimina os dados redundantes de backup, os quais costumavam exigir muito espaço de armazenamento em disco, podendo ser reduzidos em um décimo – ou ainda menos – do tamanho original.
Desduplicação em nível de arquivo e de bloco – os arquivos a serem copiados são comparados com arquivos que já foram armazenados. Se for um arquivo único, ele é armazenado e o índice é atualizado; se não for, apenas um ponteiro para o arquivo existente é armazenado.
Desduplicação in-line X Pós-processamento – remove as redundâncias antes de os dados serem gravados, reduzindo a quantidade de dados duplicados e o espaço necessário para o backup. Nesse caso, o processo backup será mais lento, já que os dados só serão armazenados após sua desduplicação.
Desduplicação na origem X Destino – pode ser realizada por software rodando em um servidor (origem) ou no local onde os dados de backup são armazenados (destino).
A desduplicação na origem remove redundâncias dos dados no ambiente de produção antes de eles serem transmitidos para o servidor ou backup. A desduplicação no destino é a remoção de redundâncias dos dados no ambiente de backup após o envio pela rede.
