Engenharia de Software – Modelagem de dados – Estudo de volume e classificação de conjuntos
A capacidade de armazenamento necessária ao modelo
Quando se define o modelo conceitual, não se trata de alguns aspectos físicos, como tamanho necessário para cada elemento, número de elementos por conjunto e principalmente com que frequência ocorre os relacionamentos.
Este estudo é necessário para se definir a capacidade necessária de armazenamento físico. Pode-se armazenar em meio magnético um conjunto de diversas formas, pode ficar em arquivos simples (sequenciais), em arquivos de tamanho variado, arquivos indexados em sistemas gerenciadores de banco de dados ou mesmo dentro do código de aplicativos.
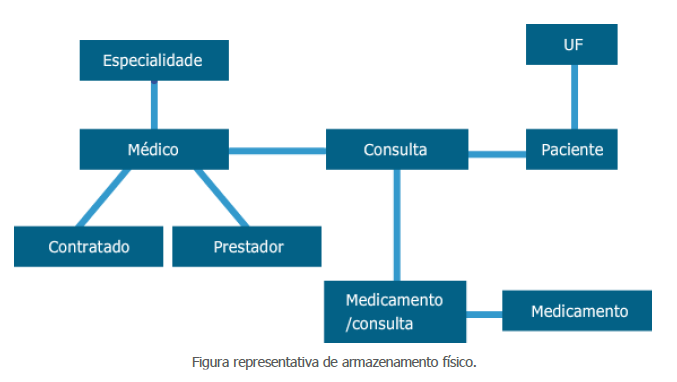
Com os seguintes atributos:
- Especialidade (cod_especialidade, nome)
- UF (Sigla_UF, nome, região, população)
- Médico (cod_médico, nome, endereço, CRM, especialidade, CPF, telefone)
- Contradado (cod_médico, dia, hora, número_contrato)
- Prestador (cod_médico, localidade, preço_base, data_início)
- Consulta (cod_médico, dia, hora, especialidade, paciente)
- Paciente (paciente, nome, endereço, telefone, CPF)
- Medicamento (código_med, laboratório, nome, preço, posologia)
- Medicamento/consulta (cod_medicamento, cod_médico, cod_paciente, dia)
Durante a entrevista com o usuário, que deve validar o projeto, já se busca informações sobre as necessidades físicas do modelo.
Primeira etapa
Verifica-se o modelo fazendo o levantamento dos volumes hoje e a taxa de crescimento anual, ou qualquer período para avaliação do modelo. Sugere-se anual, pois o planejamento da empresa, normalmente, é feito anualmente. Vai se analisar por etapas, por motivos didáticos:
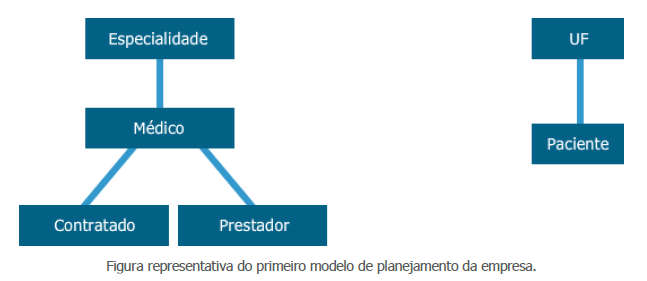
Determina-se para os conjuntos mostrados as seguintes informações verificadas com o usuário:
- Médico: a clínica trabalha com cem médicos atualmente e a taxa de crescimento é de 5% ao ano.
- Contratado: apenas 20 médicos são contratados e a clínica esta migrando para prestadores, portanto a taxa de crescimento é zero %.
- Prestador: 80 médicos restantes são prestadores de serviço e todo o crescimento será nesse subconjunto, portanto 5% ao ano.
Neste ponto verifica-se que 100% do conjunto de médicos estão representados nos subconjuntos. Especialidade: a clínica tem 20 especialidades e pretende crescer a 10% ao ano. Foi verificado com o usuário que existem especialidades para as quais não há médico, e algumas especialidades com mais de um médico e todo médico tem uma (apenas uma) especialidade.
Existem no máximo 30 UF, segundo informações do usuário e todo cliente é cadastrado. Uma UF tem crescimento zero, pois não é comum se criar UF, e tem-se 50000 (cinquenta mil) clientes cadastrados, este cadastro foi construído nos últimos anos, mas a clinica só atende clientes previamente cadastrados.
Veja que podem existir UF que não tem nenhum cliente cadastrado. Foi informado que a média é de 3000 clientes por UF. Donde se conclui que se deveria ter 3000clientes*30 UF= 90000 clientes e o usuário informou 50000 caracterizando uma inconsistência.) usuário confirma a media de 3000 clientes por UF portanto, deve-se considerar 90000 (noventa mil) clientes cadastrados.
A taxa de crescimento foi informada ser de 20% ao ano. Pode-se fazer a tabela:
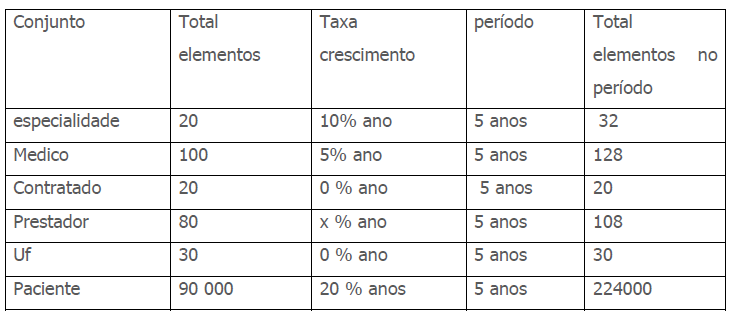
Os valores finais consideraram o crescimento em cima do crescimento e foram arredondados para o inteiro mais próximo.
Continuando nossa análise para outra parte do diagrama.
Que se tem 100 médicos e 90.000 pacientes deduzidos da fase anterior. A consulta é uma associação de médico e paciente e o usuário informou que são feitas em média 2000 consulta por dia. Neste ponto é importante qual o tempo de armazenamento. Qual o período que se deve manter o conjunto? O usuário nos informa que os dados devem estar disponíveis por seis meses, pois pode haver questionamentos ou mesmo fiscalizações sobre os dados. Desta forma considera-se 180 dias, neste exemplo, mas deve-se verificar o período para cada caso. Este período de tempo de vida do dado também pode ser definido pelo administrador de dados como será visto na próxima aula. Considerando 180 dias e o volume de 2000 consultas por dia deve-se ter uma capacidade para 360 000 elementos e a taxa de crescimento foi definida como 20% ao ano. O conjunto de medicamentos é constituído de títulos de medicamentos. E o usuário confirma um total de 5000 títulos encaminhados pelos laboratórios farmacêuticos a taxa de crescimento deste conjunto, segundo o usuário é da ordem de 5% ao ano. Foi informado também que a média de especificação de remédios é de três por consulta e que existem consultas que não são receitados nenhum remédio. Desta forma tem-se para seis meses 360 000 consultas e considerando a média de três por consulta tem-se 3*360 000 = 1080 000 elementos com a taxa de crescimento igual a de consultas ou seja 20% ao mês.
Com estas informações pode-se completar a tabela de volumes:
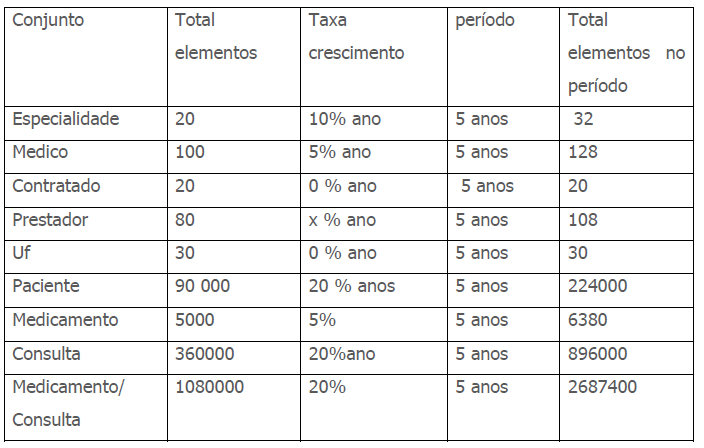
A tabela acima mostra os volumes de cada conjunto no prazo de cinco anos, o leitor pode argumentar que houve exageros nas estimativas, e poder-se-ia rever os dados da tabela. Não se fará isto, pois o objetivo é chamar atenção que deve ser determinado os recursos necessários para o crescimento da empresa. Pode-se definir inclusive estratégias anuais para ir incrementando estes recurso. O que não pode é se considerar os dados de hoje esquecendo que um projeto de sistemas de informações (ou de outra natureza) leva um determinado período para sua construção e é comum os analistas não considerarem estes prazos e implantam sistemas que já estão esgotados nos seus recursos mesmo antes de entrar em operação.
O segundo passo é determinar o tamanho necessário para cada elemento. Define-se que a unidade de armazenamento é o caráter, o que será tratado como equivalente a um byte. As linguagens de programação definem tipos de dados como inteiro, real e outros. Elas têm tamanhos definidos para tipos como inteiros que algumas linguagens que tratam com seis bytes, outras com quatro bytes esta definição depende do implementador da linguagem. O mesmo ocorre para reais. O que está fazendo é uma estimativa da ordem de grandeza de modo que se vão introduzir algumas simplificações para facilitar o cálculo. Vai se aproximar o tamanho sempre para a ordem decimal superior. Assim 8 será considerado como 10 (esta se considerando uma margem de compensação E um. Kilobyte (1024 bytes) será considerado como mil assim tem-se 24 bytes de segurança.
Sobre a tabela de atributos
Tomando a tabela de atributos:
- Especialidade (cod_especialidade, nome)
Considerando a taxa de crescimento, ter-se-á 32 elementos, de modo que a chave de identificação o cod_especialidade precisará de 2 posições (pode representar números de zero a 99) e ainda haverá uma grande folga de segurança. Pode-se definir o nome com 20 caracteres. Veja a vantagem de se trabalhar com meta dicionário, se não o está usando, e deve-se tomar cuidado ao definir esse tipo de campo nos outros conjuntos.
Especialidade precisa de 2 + 20 caracteres, portanto, arredondando, de 30 bytes.
- UF (sigla_uf, nome, regiao, populacao)
O mesmo raciocínio do identificador pode ser usado para UF. A sigla de UF deverá ter dois caracteres.
- Medico (cod_medico, nome, endereco, crm, especialidade, cpf, telefone) cod_medico é o identificador e tem-se que no futuro precisa-se de espaço para 128 médicos há necessidade de espaço para 3 caracteres (representa números de zero a 999) que garantem uma boa folga.
O nome do médico será definido com 30 caracteres, caso seja necessário espaço maior sugere-se a simplificação do nome. Veja que esse tamanho varia de cultura para cultura.
O endereço ficou padronizado em 30 caracteres, seja que só se está tratando do nome do logradouro e número.
O CRM representa a identificação de um médico e depende do Estado, considerou-se o tamanho máximo de 10 caracteres, mas isso deve ser verificado com o usuário. Ou seja, considera-se o tamanho exigido para o maior Estado.
- Contratado (cod_medico, dia, hora, numero_contrato)
Considera-se que cod_medico já foi definido com três caracteres. Dia foi definido no dicionário de dados que é da forma dd/mm/aaaa, onde d é o dia, m o mês e a é o ano, assim têm-se 8 caracteres para representar a data. Para hora foi especificado o formato HH:MM:SS onde H é hora, M é minuto e S segundo, assim têm-se 6 caracteres (não se conta os elementos de formatação). O número de contrato tem formato definido no dicionário como SS/SS/AAAA onde S é um sequencial de quatro caracteres e A é o ano com quatro caracteres. Desta forma têm-se 8 caracteres.
O elemento do conjunto contratado necessita de 3 + 8 + 6 + 8 = 25 caracteres, que são arredondados para 30 caracteres.
- Prestador (cod_medico, localidade, preco_base, data_inicio)
Para este conjunto tem-se que cod_medico tem três caracteres. Localidade é a cidade que o médico atende e definiu-se com 40 caracteres. O preço base é quanto foi negociado com o médico por atendimento e foi definido com o usuário que o valor máximo é de R$150,00, desta forma, necessita-se de 5 caracteres para representar o número, mas para evitar o risco de aumento vai se considerar 6 dígitos. A data_inicio representa quando começou a valer o atendimento, e já definimos que uma data tem 8 caracteres (DD/MM/AAAA). Assim, cada elemento precisa de 3 + 40 + 6 + 8 = 57 caracteres, arredondando, 60 caracteres.
- Consulta (cod_medico, dia, hora, especialidade, paciente)
Cod_medico já foi definido com 3 caracteres, data foi definida com 8 caracteres, hora foi definida com seis caracteres, especialidade foi definido com dois caracteres. O que não foi definido foi paciente. Verifica-se no estudo de volumes que se deverá ter 224 000 clientes cadastrados e deduz-se que se precisa de um identificador de 6 dígitos para atender ao modelo. Então, cada elemento do conjunto consulta precisa de:
3 + 8 + 6 + 2 + 6 = 25 caracteres, arredondando para 30 caracteres.
- Paciente (paciente, nome, endereco, telefone, cpf)
Já se definiu que paciente deve ter 6 caracteres. O nome deve ter o mesmo tamanho do nome de médico, que é de 30 caracteres. O mesmo raciocínio vale para endereço com 30 caracteres, idem para CPF com 11 caracteres e telefone com 16 caracteres. Cada elemento necessita de: 6 + 30 + 30 + 11 + 16 = 93 caracteres, arredondando, 100 caracteres.
- Medicamento (codigo_med, laboratorio, nome, preco, posologia)
Há necessidade de se identificar aproximadamente 7000 medicamentos e para isso precisa-se de um identificador com 4 dígitos (representa números de zero a 9999).
Laboratório – indica o nome do laboratório e usar-se-á 20 caracteres para isso, se for necessário abreviar nomes maiores que esses. Nome refere-se ao nome de remédios – definiu-se 30 caracteres para isso. Preço, segundo o usuário, existe remédios que custam até R$3000,00, neste caso vai se definir o tamanho de 6 caracteres. A posologia é a forma de utilização e destinou-se um espaço de 40 caracteres para essa descrição. Um elemento desse conjunto precisa de:
4 + 20 + 30 + 6 + 40 = 100 caracteres, não havendo necessidade de arredondamento.
- Medicamento/consulta (cod_medicamento, cod_medico, cod_paciente, dia)
Neste conjunto a maioria dos tamanhos para os atributos já está definida. Assim, precisa-se de 4 dígitos para o código do medicamento, 3 dígitos para o cod_medico, 6 dígitos para código do paciente e 8 dígitos para o dia. Então cada elemento desse conjunto precisa de: 4 + 3 + 6 + 8 = 21 elementos, arredondando, 30 posições.
Com os dados acima pode-se montar a tabela:
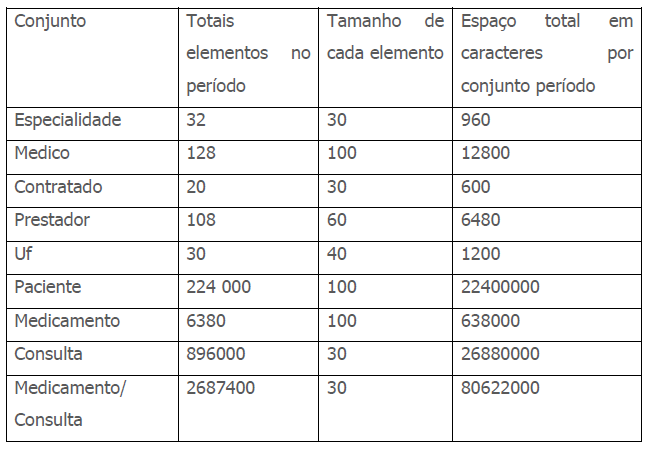
Total necessário para armazenar o modelo: 130.562.040 bytes
Arredondando-se dividindo por mil e aproximando-se para cima tem-se: 130. 563 Kilobytes.
Arredondando-se para cima tem-se: 131 Megabytes
Veja que o valor é uma estimativa. Para arquivos sequenciais pode ser considerado, mas se usamos outros produtos como SGBD há necessidade de se acrescentar um acréscimo para se considerar os arquivos de indexação, de acesso e de auditoria, ma 131 Megabytes é uma ordem de grandeza, então se pode colocar um % sobre este valor, como por exemplo, 50 % para usar um banco de dados relacional, neste caso serão necessários uma ordem de grandeza de 131 Mega + 65 Mega = 196 Megabytes.
Existe a lenda que o meio de armazenamento é barato e que não há necessidade de se preocupar com estes valores, mas hoje, com armazenamento em nuvem, transferência para dispositivos móveis e dispositivos com muitas funções e pouca capacidade de armazenamento conhecer a grandeza de armazenamento é fundamental.
Os tipos de conjuntos e seu tratamento físico
Duas características são muito importantes para se determinar o tratamento a ser dado para a utilização de um conjunto: o volume do conjunto e a volatilidade. O volume refere-se à quantidade de elementos no conjunto.
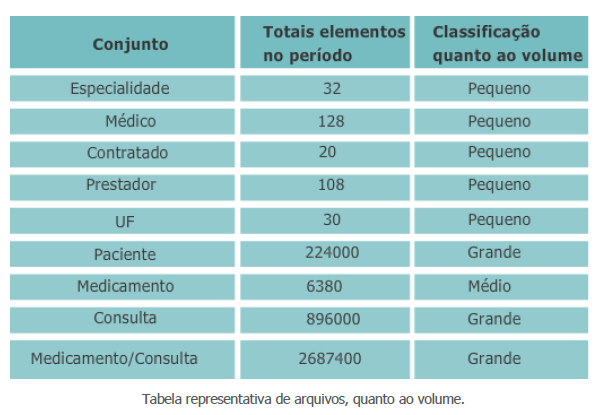
Normalmente são classificados como de grande, médio e pequeno volume. Esse tipo de classificação é muito relativo em relação aos volumes que se está tratando, por exemplo, em um sistema de telefonia que trata 200 milhões de chamadas por dia, um arquivo de 100 000 elementos pode ser considerado pequeno; para um sistema que trata de vendas 100 000 elementos é um arquivo grande. Não se trata desse tema com essa precisão. Neste trabalho a ordem de grandeza será a referência. Se o conjunto que se está tratando é da ordem de grandeza de dezenas de elementos será considerado como pequeno. Se a ordem de grandeza é de centenas o arquivo será considerado médio, e grande, se for da ordem de grandeza de milhares.
Assim, no nosso exemplo do tópico anterior podem-se classificar os arquivos conforme a tabela, quanto ao volume:
A volatilidade
Outra característica importante é a volatilidade. Um conjunto precisa que seus elementos sejam todos inseridos, mas após a inserção diz-se que o conjunto está em regime de trabalho, isto é, está estável. Durante a utilização desses conjuntos novos elementos são inseridos, elementos são alterados ou deletados, essa movimentação do conjunto é chamada de volatilidade do conjunto. O tratamento desses conjuntos deve considerar a volatilidade.
A volatilidade representa a instabilidade no conjunto, por isso, deseja-se utilizar conjuntos com baixa estabilidade. Existem estruturas de armazenamento que foram projetadas para armazenar conjuntos de baixa estabilidade e os conjuntos de alta volatilidade comprometem o desempenho dessas estruturas. Um SGBD, por exemplo, quando armazena um registro em um arquivo, gera vários outros registros de controle e de desempenho. Então não se grava um registro, mas vários outros para cada entrada. O SGBD foi projetado para trabalhar com estruturas de baixa volatilidade.
Considerar uma estrutura de baixa volatilidade quando em regime de trabalho não movimenta mais de 3% dos registros em um único processamento. A volatilidade será alta acima desse valor. Então os conjuntos podem ser classificados para o seu tratamento, quanto ao volume e volatilidade. Pode-se classificar da seguinte forma:
- conjuntos com baixo volume e baixa volatilidade são chamados de Tabelas.
- conjuntos com médio/alto volume e baixa volatilidade são chamados de Cadastros.
- Conjuntos com médio/alto volume e alta volatilidade são chamados de Arquivos de Movimento.
Os arquivos de movimento devem ser tratados fora de estruturas de armazenamento indexadas, pois comprometem o desempenho, o ideal é tratá-los com arquivos sequenciais de tamanho fixo ou não.
As tabelas, dependendo da estabilidade da tabela (perto de zero), como por exemplo, UF, se as inclusões, alterações ou deleções são muito raras, devem ser armazenadas no código dos programas, isso evita carregar estruturas toda vez que for necessário durante o processamento, barateando o sistema. Caso haja necessidade de alteração deve ser feita por uma manutenção no código.
Os cadastros devem ser armazenados em estruturas que facilitem a recuperação, tais como sob arquivos indexados. Os arquivos de movimento não devem ficar em estruturas estáticas quando se tem em um único processamento uma movimentação de mais de 3% do conjunto total. Devem se armazenar em estruturas estáveis os dados quando se faz processamento online, pois se opera um elemento do conjunto por processamento.
Se existe um conjunto que está em um banco de dados e precisa ser atualizado em um mesmo processamento batch, esse arquivo deve ser baixado para sequencial e então fazer o processamento, após o término ser carregado no banco com utilitários próprios.
Atividade proposta
Considere o diagrama abaixo retirado do livro de PERKINSON, Richard C. (Data Analysis: The Key to data base Desing. North-Holland).
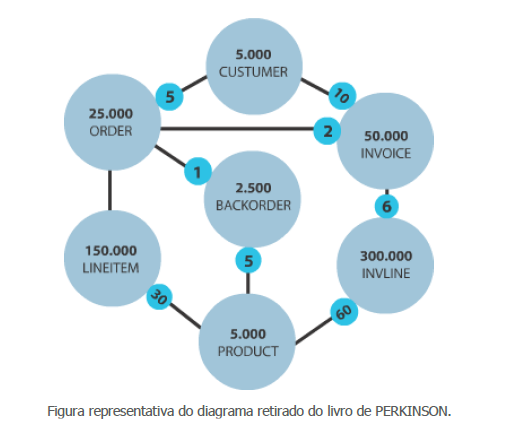
Considerando que cada elemento do conjunto tenha no máximo 100 bytes, qual o tamanho aproximado necessário para armazenar o modelo?
Chave de resposta:
Total de elementos em cada conjunto:
- Customer: 5.000
- Order: 25.000
- Invoice: 50.000
- Backorder: 2.500
- Lineitem: 150.000
- Invline: 300.000
- Produtct: 5.000
Considerando um tamanho fixo de 100 bytes por elemento, tem-se:
100 * (5.000 + 25.000 + 50.000 + 2.500 + 150.000 + 300.000 + 5000) bytes. = 100 * 537.500 bytes = 53.750.000 bytes => 53 750 kilobytes => 54 megabytes.
Referências
MACHADO, Francis Berenger et al. Arquitetura de sistemas operacionais. LTC
PERKINSON, Richard C. Data Analysis: The Key to data base Desing. North-Holland.
Material retirado da web
Engenharia de Software – Modelagem de dados – Estudo de volume e classificação de conjuntos
